Start with the Context Window
Whether that external context is stored in files or folders, or in a database or a graph, matters less than the externalisation itself - that the context exists externally, and that it can be easily and efficiently updated and retrieved when required.
the reddit roasting
last week I posted some ideas and suggestions in the self-hosted sub-reddit on using a structured database as an alternative to .md files for personal knowledge management.
i was lightly roasted.
the post was removed, but you can see the comments here.
the nature of the debate
people have very strong opinions about storing knowledge.
in one camp, you have simple files/markdown.
on the other side, you have highly structured graphs and/or databases.
some people believe, that everything should be simple, flat files and folders. others think everything should be a graph.

on a recent episode of latent space - swyx and Jeff Huber (Chroma), interview Aaron Levie from Box. around 46 mins in (i hope the video shares from this spot) they discuss the debate.
start with the context window
at the end of the day, there is only the context window - and how you fill it.
whatever system/structure you build - markdown files, graphs, databases, the job is to fill the context window in the most efficient way possible.
even in a world of infinite context; a world where we've solved 'continual learning' and 'memory', building and providing the right context will still be important.
Drew Breunig was one of the first to really bring attention to this - bigger context windows don't automatically mean better results. context gets poisoned, distracted, confused, and clashed. what you put in matters more than how much you can fit.

it's almost always the case that on every interaction you have with a language model, you will want to start with a carefully constructed base of context (mindful of cache - which is a separate, but related conversation). and that context will often need to be different depending on the situation.
there's also something to be said for Karpathy's 'cognitive-core' here. given sufficient context, a relatively small model could cover a significant amount of required user needs.
externalising context
the key idea is externalising context.
Knowledge shouldn't stay inside your head, and it shouldn't stay trapped inside any single service or provider.
Whether that external context is stored in files or folders, or in a database or a graph, matters less than the externalisation itself - that the context exists externally, and that it can be easily and efficiently updated and retrieved when required.
dynamically populating the context window
when I use the term 'agent' moving forward, i'm just referring to any system 'running tools in a loop to achieve a goal' - Simon Willison's definition.

agents should be able to dynamically pull and construct the right context, at the right time, to achieve the job at hand.
so the question becomes - which system allows the agent to populate the context window most effectively for my given task?
the write-back loop (the flywheel)
the system cannot just be read-only.
in a world of increasing underlying intelligence, and inreasingly autonomous agents (subagents - as swyx puts it),
you should not only be reading from an external corpus of context, but also dynamically writing back to an external corpus of knowledge.
the agent should also be able to write back.
each interaction should generate new external context, context that can then be retrieved later.
over time this creates a context flywheel - or context machine.
- agent pulls context
- agent solves task
- agent writes knowledge back to the corpus
- repeat
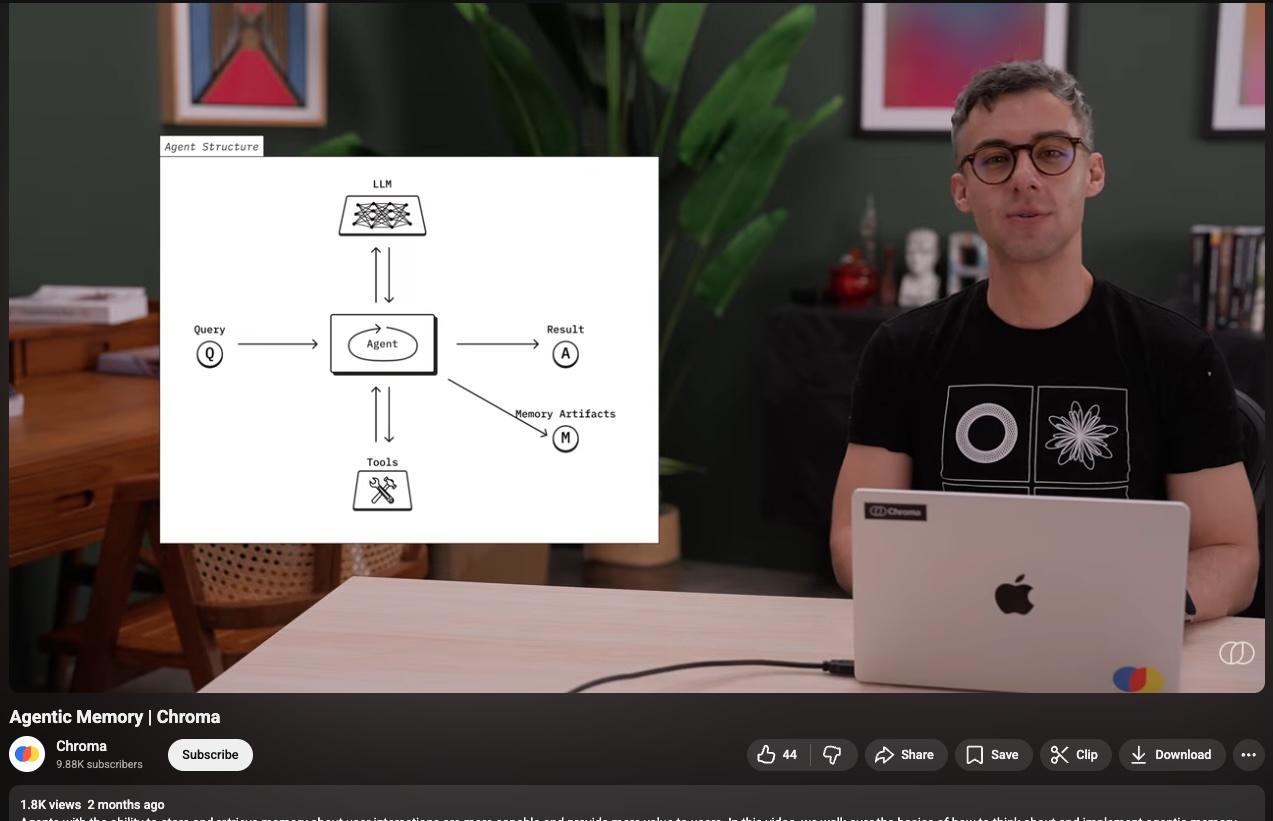
the Chroma team are exploring this same idea - they call it agentic memory. agents that remember what worked, store facts and instructions, and reuse them on the next run. same flywheel, different framing.
start with the context window
The mistake is starting with architecture; we should worry less about graph versus markdown versus database.
start with the problem you're trying to solve, then ask what structure helps populate the context best?
sometimes flat files and flexibility will be fine, sometimes structure will be better.
sometimes both, and sometimes it mightn't even matter.
what actually matters is what ends up in the context window, how reliably it gets there and whether or not the system improves itself over time.
i'm currently experimenting with this stuff.
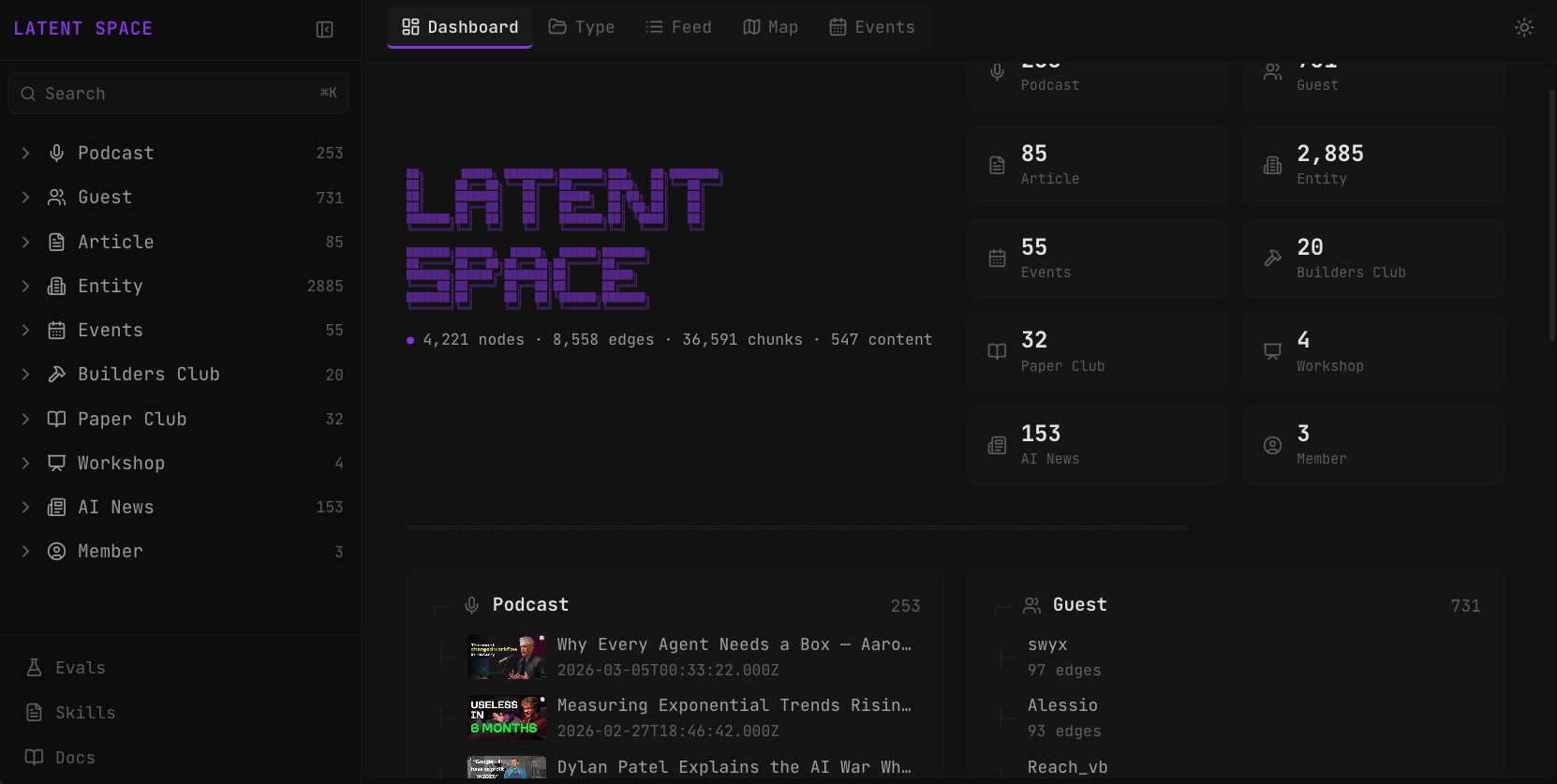
i'm building a corpus of knowledge for the latent space community. as to not trigger a religious war, i'm taking the agnostic middle and calling it a 'wiki-base' - it's a hybrid collection of both markdown files - skills and documentation, and also a structured database storing and mapping all important content and entities.
you can check it out here.
references
- Andrej Karpathy - The cognitive-core - a few billion parameter model that maximally sacrifices encyclopedic knowledge for capability
- Drew Breunig - How Long Contexts Fail - context poisoning, distraction, confusion, and clash
- Simon Willison - Agents - an LLM agent runs tools in a loop to achieve a goal
- swyx - Subagents - increasingly autonomous agents and the shift to agentic systems
- Chroma - Agentic Memory - persisting agent context across runs with semantic, procedural, and episodic memory
- Chroma - Agentic Search - iterative retrieval where agents plan, execute, evaluate, and refine searches
- Latent Space Hub - Overview - a wiki-base for the latent space community
- Latent Space Podcast - swyx, Jeff Huber & Aaron Levie - the debate on files vs structured data for AI context
- r/selfhosted - Original post comments - the roasting that started this