Free the Claw. Agents break containment, what’s next?
What happens when agents leave the chat box and coding harness, and start operating across everything else.
Here is a giant red lobster standing outside AI Engineer (@aiDotEngineer) London.

The interesting part of this story is not the giant lobster, but how it got there.
“I saw this viral tweet about how somebody put a claw in Wall Street next to the Wall Street bull. And I was like, “that's funny. We should put a claw in front of our conference." .. so, I asked Devin to research - ‘Where can I get a lobster in London?’ Devin comes back with phone numbers and email addresses and websites and I just click through”.
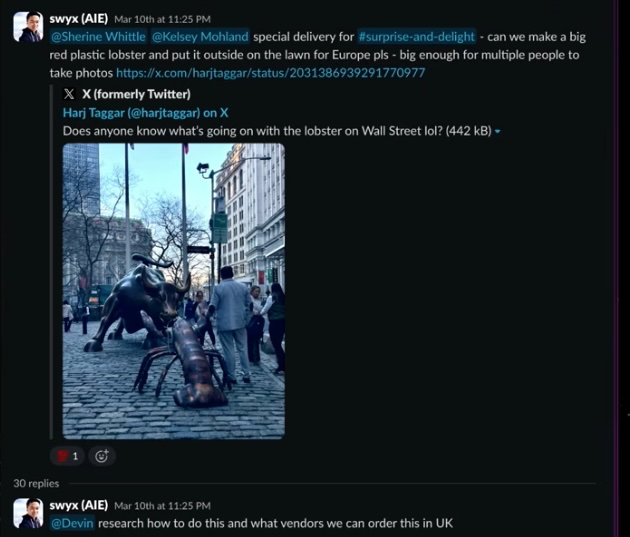
You can watch the talk here. [1]
If 2026 is the year agents break containment[2], there is a lot of work to be done. How do we design the loops that make agent autonomy useful, reliable, and aligned with user intent? We’ll unpack what it means for agents to break containment, why OpenClaw became the early proof point, and why ‘verification’ becomes the bottleneck as these systems scale.
Agents break containment
What does it mean for an agent to break containment?
About a year ago, Andrej Karpathy described the progression to software 3.0. [3] From humans writing explicit code, to training neural nets, to the prompt becoming the program.

Late last year, the prompt really became the program. [4]
“I would say in December is when it really .. flipped. where I went from 80/20, to 20/80, writing code by myself versus just delegating to agents.” - Andrej with Sarah Guo (@saranormous) [5]
A quick succession of new model releases and improvements pushed coding agent capabilities across some threshold - almost overnight, there was a clear jump forward in competence and coherence.
“Agents breaking containment” is what happens when Software 3.0 stops living inside a chat box or IDE, and starts operating across everything else.
Agents with claws.

In many ways, OpenClaw was the first real leap into the uncharted territories of software 3.0, outside the coding harness. It’s the fastest-growing open-source project in history - from 0 to 346K stars in under five months. [6][7]
It turns out the same breakthroughs in coding agent capability - agents inspecting a code base, finding bugs, and turning specs into PRs with increasing reliability - also work outside code, as long as the agent can ‘close the loop’.
Turning a conference idea into a giant red lobster is one example, Personal AI Assistant is another.
Autonomy needs a loop
Up until this point, most people's interactions with LLM’s (outside of code) have taken place within the containment chamber - the narrow chat-bot. Once an agent leaves the chat box and coding harness, the problem space changes.
OpenClaw was the first real example of this. The most crude explanation for why it got so popular is listed directly on the site - “The AI that ‘actually’ does things”. [6]
I really like Alex Krentsel’s (@AlexKrentsel) “Principles for Autonomous System Design: OpenClaw Deep Dive” [8], so that’s what we’ll use to understand exactly how OpenClaw breaks containment and closes the control loop by observing actions, results and deciding next steps.
“At the end of the day, all systems boil down to LLM calls. The difference is the context provided.” [8]

One way to explain the progressive autonomy of agents is that each new agent system wraps another loop around the LLM call.
“progression over time has been increasing loopiness”. [8]
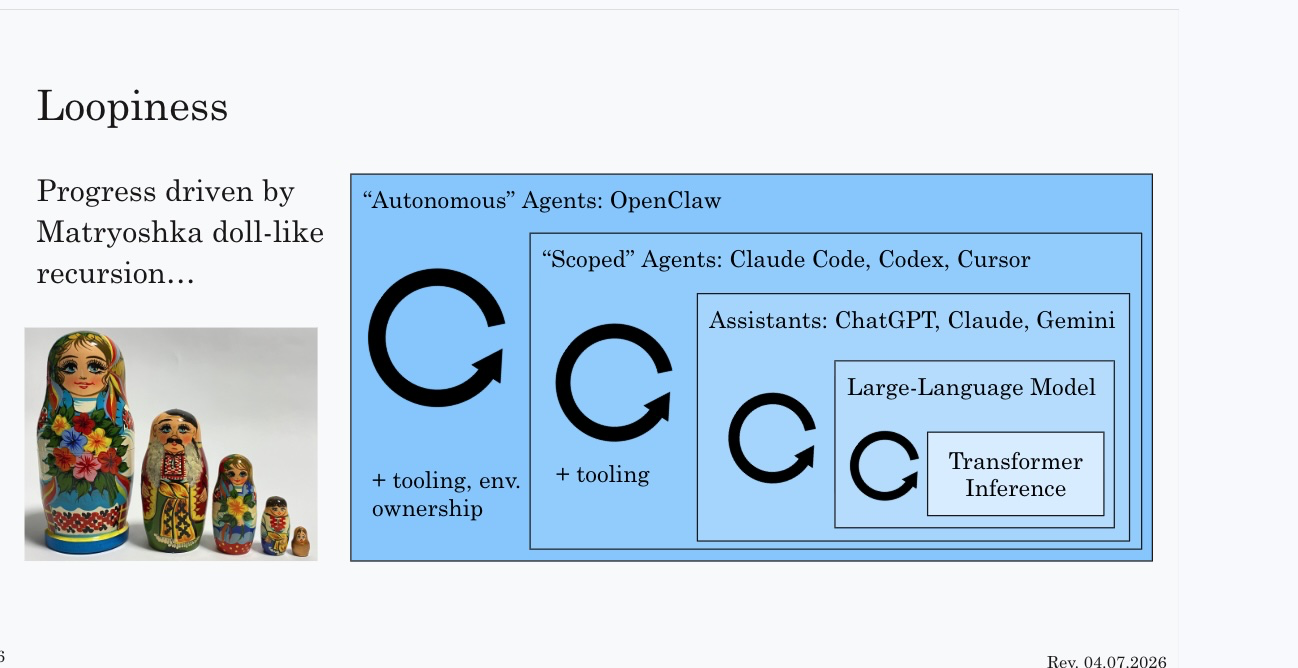
The agent is no longer just calling a fixed set of tools in a narrow chat loop - it needs the ability to navigate ambiguity rather than stopping whenever the path is unclear.
It can operate across sessions, pickup/discover capabilities through skills and extensions, schedule future work, respond to events, and keep checking in with itself (and you) over time. There is a transition from ‘scoped tool use’ to something closer to ‘dynamic tool and workflow discovery’. [9]
If you’re interested in understanding how it all works, watch the video - it’s only an hour. He has carefully sifted through the codebase and extracted the most important parts - connectors (how humans reach the agent), coordination layer (routing, sessions, memory), agent runtime, and spent time unpacking the key abstractions.
Personal agents for everything else
The current proliferation of the ‘personal agent that actually does stuff’ boils down to this idea of enabling a system to ‘close the loop’. OpenClaw was the genesis, but we’ll see many other implementations serving different requirements and scope - Hermes and Nano-claw are two interesting examples. [10][11]
Singapore’s foreign minister recently shared his self-hosted NanoClaw setup. [12]
The labs will push their own internal agentic products with increasing autonomy and loopiness, giving users every excuse to execute their agentic workflows without leaving provider applications.
OpenAI recently launched /goal in Codex CLI, which allows you to specify a durable objective up front and it will - "keep working toward this objective until it is actually done, verify against the current state, and only stop when complete or blocked." [13]
Claude moving into creative tools is another example of agents breaking containment in a different vertical. Integrating with real existing creative tools - Adobe, Ableton, Canva etc. [14]
There is some tension between the open agent harness (like OpenClaw or NanoClaw) and foundational model providers, and the delicate attempt to balance user adoption, retention, safety, discounted token subscriptions and API usage.
OpenAI hired OpenClaw creator Peter Steinberger and said the project would move to a foundation and remain open, while Anthropic appears to be pushing more activity back through its own product surface. [15][16]
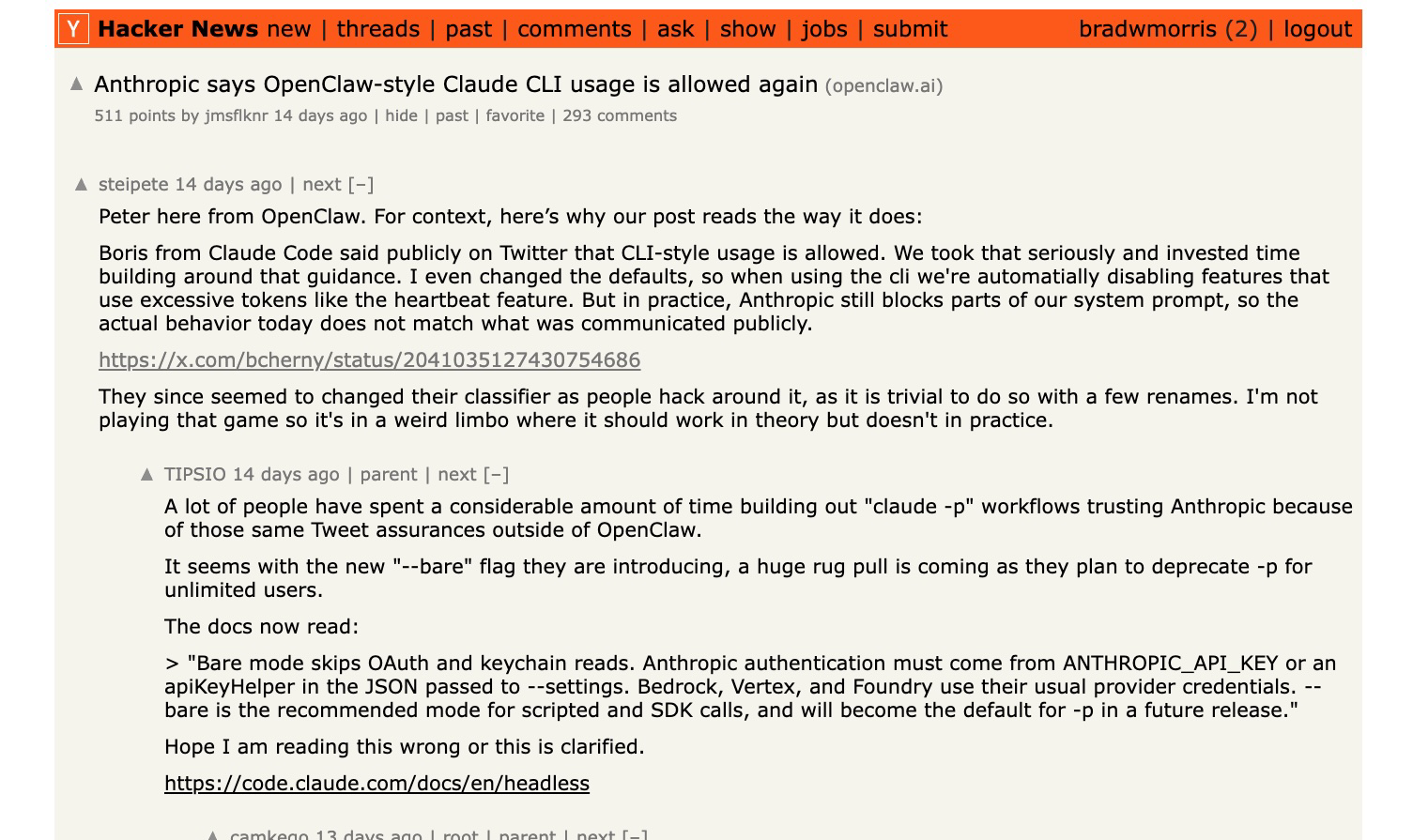
It will be interesting to see how this plays out.
The Loop gets harder to close as autonomy scales
The current personal agent use case discussed so far is relatively low stakes. But as autonomy scales, so does the challenge of closing the loop.
In this conversation, Aaron Levie (@levie) makes the case that the entire economy is downstream of code, and is about to go through the same process of adapting to this new agentic workflow.
“We basically adapted to how the agent works. All of the economy has to go through that exact same evolution. The rest of the economy is going to have to update its workflows to make agents effective and to give agents the context that they need.” [17]
We’re already seeing smaller, nimble, ai-native companies embrace the shift. Swyx’s AI engineer talk details a nine full-time people, running a $9 million+ business, using agents to do more of everything across the entire business surface. [1]
But doing this at scale is a far gnarlier challenge, especially for the incumbents, and especially considering adoption of these new agentic workflows is uneven.
Steve Yegge (@steve_yegge) suggests 70% of engineers are stuck in the bottom rungs of agent adoption. [18]
There are counter examples to this. Rapidly growing agent-native organisations (not just engineering, but the entire company) operating in the upper rungs of the adoption ladder. [19]
But there remains a huge amount of work to ensure everything in the economy downstream of code and ai-native companies adopt robust, useful and ‘verifiable’ agent loops.
So how do you close the loop as autonomy scales?
(almost) everything is verifiable, but ‘verifiability’ is layered
“I do think that ultimately almost everything can be made verifiable to some extent. Some things easier than others.” Karpathy - AI Ascent. [20]
A big part of closing the loop is ‘verifiability’.
If almost everything can be made verifiable, then almost everything can eventually be automated. This is a big deal for obvious reasons. However, as we’ll discuss - verifiability is rarely binary. Every domain has parts that are easy to verify and parts that are hard to verify.
Code went first not because code is easy, but because there are relatively strong feedback loops (verifiability). Tests pass or fail. Builds compile or they don't. Types check. Diffs can be reviewed. Frontier labs are incentivised to build RL environments around domains with large chunks of ‘easy verifiability’ and high economic utility. Math and code are the obvious wins. They have dense reward signals, economic value, and lots of existing infrastructure and training data.
So a large part of the story of increasing autonomy is - train and deploy with a strong verifiability loop, and give the model access (the harness) to a few simple tools and interaction surfaces - a shell, a file editor and an execution environment.
But how well does the rest of the economy (domains other than code) adopt this new agentic workflow without the same pre-defined verifiability loops?
Not all knowledge work is code-shaped, with the same built-in verifiability.
And even within a single domain (such as code), verifiability isn’t binary - it’s a property of parts of work within a domain. Every domain has easy to verify parts, and hard to verify parts.
In software, the verifiable slice can be large - does it compile? do the tests pass? does the diff look correct? The less-verifiable slice is everything else - is this the right thing to build? Is the architecture sound? Is it maintainable? Does it actually serve the user?
In his 2025 AIE talk, Sean Grove said the following:
"The new scarce skill is writing specifications that fully capture the intent and values. And whoever masters that again becomes the most valuable programmer." [21]
I highlighted ‘fully capture the intent and values’ because while the verifiable slice gets you surprisingly far, it’s often never as clean and simple as “does it compile”?
This explanation from @badlogicgames captures it well.
“the best spec is the actual program. anything you leave blank in your spec, the agent will fill with what it's learned. it learned from all our code on the internet plus some RL training. most of the code it saw is horrible.” [22]
As models continue to improve and get exceptionally good in certain domains ‘inside the weights’, the lack of general understanding - the jaggedness, becomes more pronounced and makes ‘closing the loop’ at scale a bigger challenge (and design space). [23]
“How is it possible that state-of-the-art Opus 4.7 will simultaneously refactor a 100,000 line codebase or find zero day vulnerabilities and yet tells me to walk to this car wash? This is insane.” Karpathy - AI Ascent [20]
Ultimately, models will continue to improve. But for the time being, the jaggedness remains - the path to AGI will not be straight.
As these systems are able to solve increasingly complex problems with increasing autonomy across all domains, humans will just move further up the rung of abstractions. The work shifts toward higher-level spec design, verification, context curation, data curation, where taste matters. And for the moment, scaffolding around the jagged edges.
To ensure more people can leverage these long-running agentic capabilities, even within the more verifiable domains, there is clearly still a huge amount of work to be done.
‘Grill me’ and intent clarification example
One final example to illustrate this new design space.
Matt Pocock (@mattpocockuk) has been sharing a bunch of insightful takes recently; he talks a lot about integrating good system design principles and thinking into new agentic workflows. [24]
His “Grill Me” workflow, which is essentially just a skill (painfully simple), is something I’ve implemented into almost every interaction I have with an LLM. Before the agent does the work, it interviews you until there is ‘shared understanding’. [25]
Not "ask one vague clarifying question and then sprint off." actually grill me - What am I trying to achieve? What does done look like? Where is the ambiguity hiding? Essentially building a shared understanding and language between human intent and agent.
(in my opinion) this kind of work is interesting because it respects the idea that underlying model improvements will continue (bitter-lesson), but helps people plug the gaps when working with these spiky ghost-like entities. [26] The gap may eventually be closed by model improvements, maybe even a different model architecture, maybe world models? [27]
But until then, this is where I think a lot of the interesting work will happen.
As agents break containment and close the control loop at scale, they’ll need to navigate increasing ambiguity. the hard problem is not only giving them more tools, more memory, more integrations, or longer-running loops. It is making sure the loop starts from the right, shared intent.
Purchasing a giant inflatable lobster is impressive, but if we want these systems to do more, there’s a lot of work to be done.
References
-
Swyx, AI Engineer London talk, YouTube.
-
Latent Space, "Unsupervised Learning 2026".
-
Latent Space, "Software 3.0".
-
Latent Space, "WTF 2025".
-
Andrej Karpathy and Sarah Guo, conversation on agentic coding, YouTube.
-
OpenClaw, GitHub repository.
-
Alex Krentsel, "Principles for Autonomous System Design: OpenClaw Deep Dive", YouTube.
-
OpenClaw documentation: tools, skills, cron jobs, and session model.
-
NousResearch, Hermes Agent, GitHub.
-
hustcc, NanoClaw, GitHub.
-
Linas Beliunas, post on Singapore foreign minister NanoClaw setup, X.
-
OpenAI Codex, /goal command lifecycle issue, GitHub.
-
Anthropic, "Claude for Creative Work".
-
TechCrunch, "OpenClaw creator Peter Steinberger joins OpenAI".
-
Tom's Guide, "OpenAI hires the developer behind OpenClaw".
-
Aaron Levie, conversation on agentic workflows, YouTube.
-
The Pragmatic Engineer, "From IDEs to AI Agents with Steve Yegge".
-
Ramp, self-maintaining experimentation example, YouTube.
-
Andrej Karpathy, Sequoia AI Ascent talk, YouTube.
-
Sean Grove, 2025 AIE talk, YouTube.
-
badlogicgames, spec critique, X.
-
Ethan Mollick, jaggedness example, X.
-
Matt Pocock, discussion of agent workflows, YouTube.
-
Matt Pocock, "Grill Me" workflow, GitHub.
-
Andrej Karpathy, "Animals vs Ghosts".
-
Latent Space, "Adversarial Reasoning".