Dario's Road to Valhalla
What's the most plausible story where foundation model companies actually start making money?
What's the most plausible story where foundation model companies actually start making money?
Assuming "making money" means revenue covers serving costs and leaves enough gross profit to fund overhead and the rolling cost of frontier R&D, foundation model companies start making money when inference gross profit grows faster than the cost of generating frontier tokens.[1][2]
This essay argues the most plausible path requires two things: (1) deployed models generate enough gross profit to fund the R&D treadmill, and (2) training-cost growth slows relative to revenue.
This only works if the industry settles into the steady-state oligopoly/equilibrium referenced by Dario during a recent conversation[1] - a small number of capital intensive labs locked into a fundable race, each using a substantial share of its compute to serve customers and a substantial share to train the next model. Entering the race is prohibitive because it requires enormous capital, compute access, infrastructure, and expertise.[1][9]
The equilibrium only produces sustainable profits if token demand continues to rise, serving costs keep falling, training-cost growth slows and the surviving labs remain differentiated and sticky enough to outcompete non-frontier competition.[1][7][8]
Let's call this Dario's Valhalla.
The bear case is that open models, distillation, low switching costs, hyperscalers, and app owners compress model margins before the labs turn temporary model leads into durable and sustainable profit.[18][19]
(discussed below)
The red queen treadmill
"Profitability" needs qualifying because immediate profitability in the traditional sense is not the goal (nor desirable) for the labs.[1]
Since roughly GPT-3, frontier progress has been an effective-compute race with each next model family requiring a much larger compute commitment than the last. So the cycle looks something like - (1) raise a shit-ton of money, (2) secure compute in advance, (3) train the next model, (4) deploy, repeat.[1][3][2]
Buy too little compute, fall behind. Buy too much, go bust.
The Red Queen treadmill has meant the near-term goal is not "be profitable", but to predict demand, raise capital and secure compute to allocate to serving customers and training the next model family.[3]
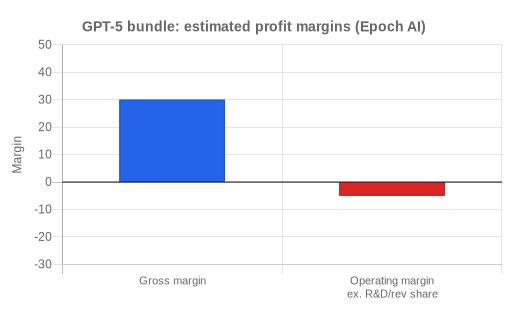
The GPT-5 bundle for example, made about $6B in revenue and spent about $4B on inference, leaving only $2B gross profit. After operating costs, the bundle roughly broke even before R&D, and probably lost money after Microsoft's revenue share. Epoch estimates OpenAI spent about $5B on R&D in the four months before GPT-5. So GPT-5 likely did not even pay for itself, let alone fund the next model. From Epoch's "Can AI companies become profitable?"[2]
Anthropic's 2028 path to profitability
We're going to focus on Anthropic, because there are some near(ish) term "profitability" targets. Dario has also spoken directly about profitability. OpenAI has much larger compute commitments and longer time horizons. Google has a structurally different profitability model.[4][1]
Anthropic is reportedly targeting break-even by 2028, with cash burn falling to about a third of revenue in 2026 and roughly 9% by 2027.[4] Though it should be noted that this forecast is from The Information, not from Anthropic. And Dario himself has expressed that both "profitability" and timing are slippery in AI economics.[1]
We're going to extrapolate from the reported 2028 predictions and create a very crude toy profitability prediction that we can work backwards from. Obviously, this could well be a long way off the actual numbers, but it gives us something to interrogate.
Here's what we do know:
- End-2025 run-rate revenue: ~$9B [13]
- Feb 2026 run-rate: $14B [12]
- April/May 2026 run-rate: >$30B; SemiAnalysis estimate: $44B+ [13][5][7]
And the reported 2028 prediction:
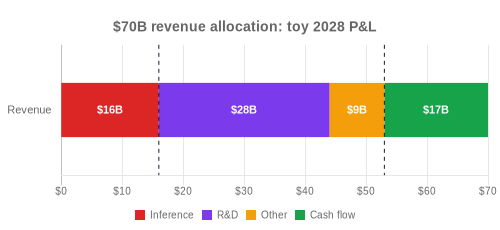
- $70B revenue, 77% gross margin, $17B cash flow [4]
A 77% gross margin means direct serving costs of about $16B, leaving roughly $54B of gross profit.[4] If $17B remains as cash flow, the other $37B has to cover frontier training/R&D and normal company costs.
In the toy version below, I'm assigning about $28B to training/R&D and $9B to everything else.
Toy model - 2028 P&L:
- Revenue: $70B
- Gross profit: $54B (77% margin, ~$16B inference)
- Training/R&D compute: $28B
- Other costs: $9B (salaries, sales, legal etc)
- Cash flow: $17B
In this world, deployed Claude generates $54B gross profit - enough to fund the rolling R&D treadmill, run the company and still leave $17B in the bank.
Compute requirements
Getting slightly above my pay grade here, but (I think) the compute checks out.
If Anthropic hits $70B of revenue at 77% gross margin, then total annual compute spend is roughly ~$44B per year.[4]
Using a very rough frontier compute-cost rental heuristic "$10B-$13B per GW-year"[9], "$44B" of compute spend corresponds to roughly 3.4-4.4 GW of average utilized capacity. So our 2028 toy prediction would require roughly ~4 GW.
Anthropic's current commitments include AWS up to 5GW, Google/Broadcom 5GW from 2027, Azure up to 1GW, SpaceX near-term, plus Fluidstack's $50B buildout.[14][13][16][5][15] Numbers here are very rough given some capacity is future, some conditional, some may overlap and "up to" is not the same as delivered.
It just illustrates that 4+GW is feasible for 2028 with wide potential variance.[14][13][16][5][15]
The fact Anthropic just announced the SpaceX partnership to free up some near-term compute constraints suggests they are already bumping up against the upper limits of initial predictions.[5]
The profit equation
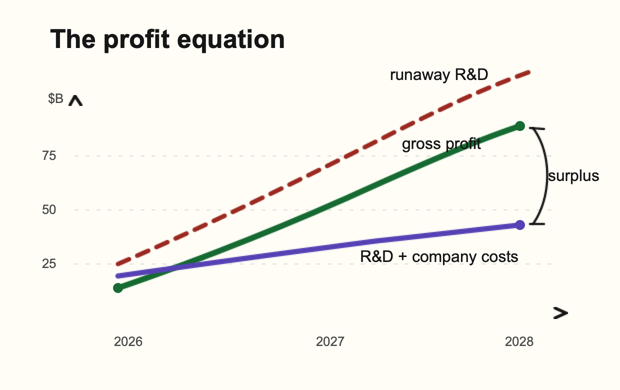
1. Can revenue double from current run-rate ($30-$40B) to $70-$80B, and gross margin climb from 40% to 70%?
Doubling revenue from a current run-rate of roughly $30B-$40B to $70B-$80B by 2028 seems plausible.[12][13][7]
These models now appear to be moving into a real opportunity zone where they can do substantial work, not just act as chatbots. With the late-2025 unlocks in coding and new agentic workflow capabilities, the case for frontier models doing a much larger share of valuable work, and therefore touching a much larger share of GDP, looks stronger than it did a year ago.[6][7][22]
However, this does not mean Anthropic automatically captures the value.
Claude would need to become deeply embedded in real enterprise workflows so customers are reluctant to rip it out and go elsewhere next quarter - Claude Code, evals, memory, permissions, procurement, and workflow integration.[1][12][13][20] We can already see a lot of competition at this layer, both from competing labs and harness/wrappers.[17][21]
Juggling subscription management, token subsidies and external API access will be both opportunity and nightmare.[20]
Public pushback and policy are also concerns - what happens when/if these models start seriously threatening a large portion of white collar work?[1]
Gross margin rises if demand for frontier tokens grows, while cost of serving them falls. There are early indicators to suggest this may be happening in SemiAnalysis's AI value-capture argument.[7] But it will require continued innovation - better hardware, utilisation, batching - the mechanics Reiner Pope walks through in the LLM training and serving conversation.[8][20]
2. Will training cost growth slow relative to revenue?
Frontier R&D cannot keep compounding on the old curve while revenue grows only linear-ishly. Annual frontier R&D would need to settle around $25-35B, not climb toward $70-100B. That could happen if supply-chain, power, and data-center bottlenecks make 10x training-run jumps physically harder, as Dylan Patel argues, while diminishing returns make each additional dollar of training less valuable.[9][1]
But this only helps Anthropic if the frontier slows after Claude has become sticky. If scaling slows while customers can still switch easily, open-weight models and cheaper rivals get more time to catch up, and the lower R&D bill comes with lower margins.[10][11][18]
The bear case. A melting ice-sculpture
The major bear case isn't that AI fails to be useful, it's that the value from useful AI accrues to everyone else.[18][19]
A good analogy is an ice sculpture.
For a few months, customers will pay to see it, developers will build on it, and enterprises will route work through it. Anthropic has to sell as many exhibition tickets as possible while that advantage lasts, but the sculpture is melting.
The problem is that ticket revenue does not all become lab profit.
Even if we reach the steady-state oligopoly/equilibrium, with just a few labs locked into a fundable race and serving the frontier tokens, there is still an entire surrounding ecosystem. The labs must have a new, state-of-the-art sculpture ready before the old one has melted.
Nvidia sells the chisels. AWS, Google and Microsoft own the freezers, and collect rent.[9][14][13][16]
Rivals and open-weight models copy, distill and sell cheaper access.[10][11][18]
Existing software, new AI-native apps and wrapper companies will also bid to own the relationship in specific verticals, and route to multiple models and cheaper alternatives when it makes sense to do so.[17][21]
Apps like Cursor have been hugely successful.
I find this example particularly interesting. Ramp, an AI-native financial services company, partnered with Prime Intellect to build small RL'd bespoke models for custom workflows and tooling, ultimately replacing some of the existing reliance on frontier models.
Dario's road to Valhalla
Sustainable profit for these labs is possible, but it won't be easy.
Even if a steady-state equilibrium is reached where a small number of labs control access to frontier tokens, they will still need to capture and maintain substantial market share.
That will require revenue to keep rising, margins to improve, training costs to stop outrunning gross profit, and customers to become sticky before the model lead disappears.[1][7][18][20]
If they can do this, Dario and Anthropic shall pass through the gates of Valhalla.
References
- Dario Amodei, "We Are Near the End of the Exponential," Dwarkesh Podcast.
- Jaime Sevilla, Hannah Petrovic, and Anson Ho, "Can AI companies become profitable?", Epoch AI.
- InvestX, "The Red Queen: AI's Spending Race".
- The Information, "Anthropic Projects $70 Billion Revenue, $17 Billion Cash Flow in 2028".
- Anthropic, "Higher usage limits for Claude and a compute deal with SpaceX".
- Andrej Karpathy, "Software Is Changing (Again)," Y Combinator / YouTube.
- SemiAnalysis, "AI Value Capture: The Shift To Model Labs".
- Reiner Pope, "The Math Behind How LLMs Are Trained and Served," Dwarkesh Podcast.
- Dylan Patel, "Deep dive on the 3 big bottlenecks to scaling AI compute," Dwarkesh Podcast.
- Anthropic, "Detecting and preventing distillation attacks".
- Nathan Lambert and Florian Brand, "The ATOM Report: Measuring the Open Language Model Ecosystem," arXiv.
- Anthropic, "Anthropic raises $30 billion Series G funding at $380 billion post-money valuation".
- Anthropic, "Anthropic expands partnership with Google and Broadcom for multiple gigawatts of next-generation compute".
- Anthropic, "Anthropic and Amazon expand collaboration for up to 5 gigawatts of new compute".
- Anthropic, "Anthropic invests $50 billion in American AI infrastructure".
- Microsoft, "Microsoft, NVIDIA and Anthropic announce strategic partnerships".
- OpenClaw, "Token use and costs," OpenClaw Docs.
- Parker Whitfill, "The Brutal Economics of Building AGI," Great Divergence.
- Alex Imas, "What Will Be Scarce?", Ghosts of Electricity.
- Anthropic, "Claude API pricing," Anthropic Docs.
- Eric Glyman, "Getting on the right side of the ice," Ramp / X.
- METR, "Task-Completion Time Horizons of Frontier AI Models".